最近花了一些时间思考“软件”这个我们每天都在用的东西,到底意味着什么。从最初的工具属性,到现在的 AI 浪潮,回到原点,把这些零散的想法整理一下。
软件
软件对于人的作用,从使用角度,其实主要是帮助人类实现某些目的,满足人类的需求的工具和手段。
- 实现人类目的
- 娱乐:游戏、内容消费
- 教育:学习、获得技能
- 工作:生产力、协作
- 生活:衣食住行、交易、健康
- 社交:连接、沟通
- 人类需求(用马斯洛作“上层框架”)
- 生理、安全、社交、尊重、自我实现、认知、审美、自我超越
- 把“目的”和“需求”拆开
- 目的(Goal):想达成的结果
- 需求(Need):达成目的时在意的东西(效率、确定性、安全感、掌控感、胜任感、归属感……)
- 产品机会点:高频目的 × 高痛需求 × 现有工具的结构性不足
软件本质

- 固定下来、抽象出来的人类习惯
- What
- 核心是了解人:软件给人使用、为人服务
- 软件做的是:为某些人群的一类需求,抽象出一套符合人类习惯、可重复执行的规则与流程
- How
- 抽象出这样的规则,首先要理解人类特点:人类基因中固有的特质 + 时间依赖的外部变化,共同塑造出人的做事方式。基于这些特点构建软件,解决用户需求。
- 人类做事特点,一部分是固有在基因中的;过程上又有时间事件序列依赖,同时受外部影响(也就是用户习惯培养)。但“习惯培养”很多时候只是把人类的一些隐形特点激发出来。
- 要了解这样的人类特点,一种方式是通过学习,提高对人的认知,了解人类习惯的 pattern,预测会有的人的行为模式,此为认知+预测。另一种是社会实验,也就是实现不同版本,获得人类的反馈,从而了解真实世界中隐藏的人类特点。
- 抽象出来的体验,与内容体验相对:Capture the underlying principles of an experience, not the experience itself。
- What
- 人类能力的增强(Augmentation:用软件做“人做不到/做不好的事”)。人类大脑虽然精密,但受限于生物机能,记忆容量有限,且难以进行大规模并发思考和行动。
- “思考”
- 超强算力与并行: 人类习惯线性思维,而软件具备指数级处理能力。同时把经验流程化、模板化(capture the underlying principles),让“质量”更稳定
- 记忆的无限延伸:对抗遗忘曲线,把知识/经历外置成可检索、可复用、可共享的记忆
- “行动”
- 跨时空协作:把个体能力扩展为网络化能力(协作、同步、沉淀)
- 使用工具:实现电子迁移到原子迁移的转化,影响环境。上个时代的 O2O 就是典型的例子。
- “思考”
因此,软件应当被视为杠杆。它不仅实现了已有习惯的“自动化”,更协助人类完成了单纯依靠生物本体无法实现的任务。这正是软件产生巨大价值的根源。
软件的运作方式
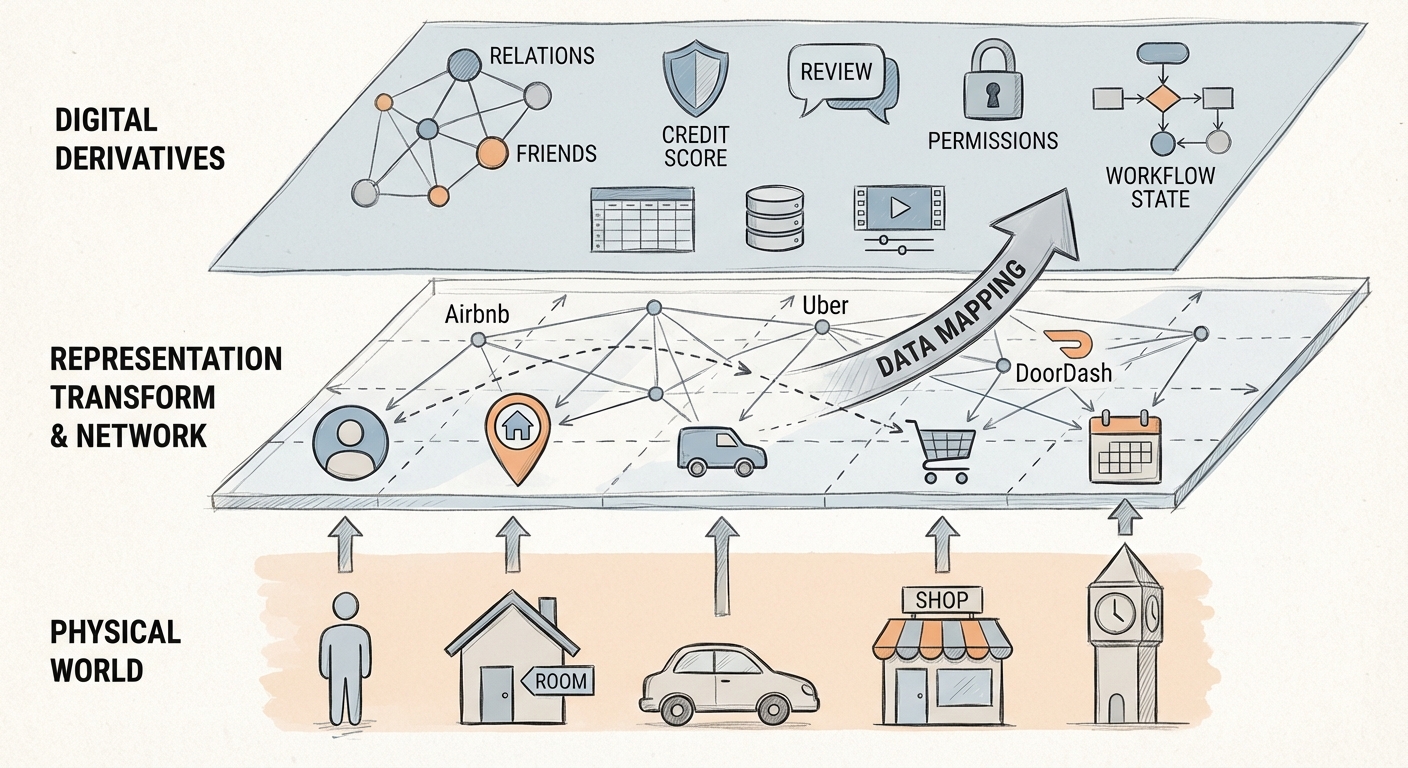
- Data mapping / representation transform
- 软件经常在做的事:把一种表征(representation)映射成另一种表征,并在这个过程中做计算、聚合、筛选、排序、生成
- 世界被“电子化”之后,出现两类表征
- 物理世界的映射:人、房间、车、店、商品、位置、时间。比如 Airbnb、Uber、DoorDash,将人、房间、车、店映射到网络空间。
- 数字世界自生的表征:关系图谱(关注/好友)、信用分、点评、权限与策略、工作流状态。再比如 Excel 的运算与呈现、数据库的 join/聚合、文字/图片/视频编辑
人机交互(HCI):一种妥协,也是一套成本管理
从根本上看,交互界面的存在,本质上是因为机器尚未达到足够的智能,而不得不采用的一种“妥协”方案。
- 交互界面为什么存在。更便利地将想法、需求转变为工具的执行,以获得结果。人需要找到适合自己的工具,以实现自己的目的和需求。不同的人有不同的需求和习惯,对应的工具很多;最合适的是契合用户需求、符合用户习惯的,也是最容易获得用户粘性的产品。用户需求是个抽象概念,需求需要有边界/范围:通常来自“高频重复的一件事”,或“一系列经常一起出现的事件链”,这些天然会形成边界。
- 意图、需求满足体验层级
- 完美: 意图产生 -> 需求即满足(Zero UI)。
- 次优: 意图表达 -> 需求被满足。
- 现实(HCI): 意图表达 -> 学习/操作/努力 -> 需求被满足。
- 当机器还不能可靠理解人类意图时,人只能用更显式、更结构化的方式表达;交互因此成为“妥协成本”。
- 好的交互不等于“让用户多操作”,而是尽量降低总成本
- 反馈回路(Feedback Loop)
- 行动 → 系统状态变化 → 用户理解 → 下一步行动(循环)
- 一个很实用的检查方式:系统要不断回答
- 发生了什么(反馈/可见性)
- 现在到哪了(状态/进度)
- 如果错了怎么办(可恢复:撤销、回滚、纠错路径)
- 意图、需求满足体验层级
- 界面形态的演化(从命令行到今天)
- 早期:DOS/终端 + 命令行(command line / CLI),用户敲命令,计算机返回结果或执行动作
- 后来:网页、App、各种 GUI
- 我对这条演化链的解释:机器越不智能,人越需要更复杂的界面来表达意图与约束
- 一个有趣的对照:如果把 LLM 接到“命令行”时代,最原始的人机交互可能反而接近聊天(chatbot);今天的 Chatbot/Agent 也在把它重新拉回来。
LLM 时代:交互从“操控(Control)”走向“协作(Collaboration)”

- 一个必须承认的变化:LLM 的反馈是概率性的。传统软件很多反馈是确定的(保存成功/失败、点赞变红),LLM 输出可能波动,甚至“看起来很对但其实不对”。因此,我们应更在意信任机制,而不是“每次都对”
- 可校验:输出能被验证(引用/依据/复现路径)
- 可追溯:系统做了什么、为什么这么做
- 可恢复:错了能低成本纠偏(撤销/回滚/替代方案)
- 可控:权限、范围、成本、风险在用户掌控中
- Pull vs Push:从被动响应到主动服务(Agent),但前提是边界清晰。
- Pull:用户主动操作,系统响应(今天大多数软件)
- Push:系统基于预测主动服务(Agent )。Push 的前提不应只是“更聪明”,也应该“更可控”
- 可授权:明确授予权限与目标
- 可边界:范围(时间/对象/金额/影响面)可配置
- 可撤销/可回滚:一键停用、撤销动作、恢复状态
- 可审计:能看到日志(做了什么、为什么、用到了哪些数据)
- 可降级:自动执行随时降级为建议/草稿/待确认
哪些人机交互在大模型的技术条件下可以有更好的体验,减少交互复杂性,更符合人类与计算机交互的nature? 欢迎评论区讨论。
📬 Stay Updated
Get notified when I publish new posts. No spam, unsubscribe anytime.
Already have an account? sign in to manage subscription.